[박찬권의 ‘SQL 튜닝공부 한번 해보실래요?’]
저자: 박찬권
방송통신대에서 컴퓨터과학을 전공했으며, 게임 개발자 출신이다. 데이터 스페셜리스트로서
SQL 튜닝, 데이터마트 설계, 업무 모델링 등 수많은 프로젝트를 성공적으로 이끌었다.
실무뿐 아니라 여러 대학 특강과 기업 특강을 통해 실력파 데이터 전문가로 인정받고 있다.
네이버 카페 '데이터와 사람들'에서 '칼찬요정'이라는 이름으로 SQL 튜닝 강의와 진로상담을
통해 팬들로부터 사랑받고 있다. 개발자 출신으로 SQL 튜닝 노하우를 집결한
[오라클 튜닝 에센셜 – DBMS XPLAN으로 SQL 실행계획 뽀개기]를 출간했다.
[이전화 보기]
제2회: SQL 문법보다 아키텍처! 오라클 아키텍처의 이해(상)
안녕하세요, SQL 튜너로 활동하는 박찬권입니다.
첫 연재라서 독자 여러분께 딱딱하지 않게 다가가려 애썼는데 어떠셨는지요? 저는 그사이에 ERP 개발 프로젝트 마무리 작업을 마치고 바로 새로운 프로젝트에 참여했습니다. 주말을 이용해서는 5주 과정의 ‘SQL 튜닝 특강’ 강의도 하고 있습니다. 늦게 퇴근하고 주말을 쉬지 못하여 가족에게 미안한 마음이 들기도 하지만, 열정적으로 살아가는 저에게 응원해주고 있어 힘을 내고 있습니다.
‘포기’에 대하여
저는 포기에 대한 저만의 기준을 가지고 있습니다.
포기에 대해 이야기를 하기에 앞서 시작에 대하여 이야기해 보겠습니다. 저는 시작을 잘합니다. 저에게 도움이 될 것 같거나 마음이 당기는 일에 대해 짧게 고민하고 바로 시작합니다. 어찌 생각하면 아이러니한 이야기일 수도 있는데요. 시작할 때의 마음가짐이 좀 다릅니다. ‘하다 힘들면 안 하면 되지.’ 혹은 ‘해 보고 재미없으면 그만둬야지’ 하는 생각으로 시작합니다. 언제든지 그만둘 준비(?)가 되어 있습니다. 그런데 반대로 ‘힘들지 않으면?’ 조금 더 합니다. ‘재미가 없는 정도가 아니라면?’ 계속해봅니다. 목표나 발전 속도, 수행 능력과는 다른 이유로 그만둘지, 계속할지를 결정합니다. 목표를 향해 달려가기보다 과정을 점검하며 진행합니다. 좋은 성과를 내더라도 하는 중에 힘들거나 재미가 없어지면 그만두기도 합니다. 그 일에 다시 흥미가 생기면 한 번 더 시작하기도 하고요.

(이미지: 영화 ‘미스 리틀 선샤인’ 중에서)
가끔은 포기가 두려워 시작을 안 하는 분을 만나게 됩니다. 혹시 여러분도 포기가 두려워 시작을 못하시나요? 아니면 ‘지금 이 나이에 되겠어?’라고 생각하면서 시작을 못하나요? 포기하면 어때요. 포기한다고 저를 잡아가나요? 또 지금 나이가 어때서요? 혹시 3년 전에 할까 말까 고민했던 것 중에 지금이라도 해볼까, 하는 게 없나요? 저는 강력하게 권합니다. 차라리 포기한다고 생각하고 일단 시작을 하세요. 시작해야 포기라는 결과도 열매라는 결과도 얻을 수 있습니다.
과정을 점검하면서 절대 하지 않는 일이 하나 있습니다. 남과는 비교하지 않습니다. 비슷하게 혹은 저보다 늦게 시작했는데도 잘하는 사람을 보면 부럽습니다. 학창 시절에는 단계별로 중간고사, 기말고사가 있기 때문에 한번 지나가버리면 그 시험을 다시 잘 치를 수 없습니다. 하지만 인생은 중간고사, 기말고사처럼 정해진 시간에 시험을 보는 것이 아닙니다. 부러우면 조금 더 하면 되고, 그래도 안되면 비교하지 않으면 됩니다. 발전하는 자신을 보세요. 오래 걸리더라도 해내고 나면 그 과정이 자신만의 스토리가 됩니다.
봄에 피는 꽃이 있고 가을에 피는 꽃이 있습니다. 가을에 피는 꽃이 봄에 피는 꽃을 부러워하지않을 것입니다. 비슷하게 시작하거나 심지어 늦게 시작한 동료가 나보다 앞서 나간다면 부러운 건 당연합니다. 그런데 그런 이유로 포기한다면 그것도 당연한 걸까요? 자, 아직 2020년 초반입니다. 어떤 거든 좋으니 시작해보세요. 저랑 SQL 튜닝을 한번 시작해 보시죠.
데이터 아키텍처를 공부해야 하는 이유
지난 연재 글과 일부 겹치는 내용이지만 본격적으로 오라클 아키텍처에 관해 설명해 보겠습니다. 오라클뿐만 아니라 어느 분야든지 공부와 배움에 있어 당장 필요한 것도 있지만, 일정 수준 이상의 지식을 쌓아 더 높은 곳으로 올라가기 위한 것도 있습니다. 오라클 아키텍처는 그런 것입니다. 오라클을 사용하는 데 SQL 문법도 중요하지만, 그것은 딱~ 공부한 만큼만 적용할 수 있습니다. 대표적으로 함수가 그렇죠. 아키텍처는 지식의 근력이 되어 일정 수준 이상 쌓이게 되면 든든한 기반 지식으로 이해의 폭을 크게 넓혀줄 거라고 확신합니다.
지금까지 오라클을 사용할 때 SQL을 어떻게 작성하였나요? SELECT, FROM, WHERE 등의 키워드를 먼저 익히고, 책이나 인터넷에 있는 몇몇 함수를 따라서 실행하는 방식으로 공부했을 겁니다. 그리고는 실전에서는 원하는 결과를 얻기 위하여 큰 고민 없이 스크립트를 만들어 실행해 봅니다. SQL을 만들어 한 번 실행해 보고 결과를 확인한 다음, 원하는 결과가 아니면 조금 수정해 실행하기를 반복하다가 결과가 예상과 맞으면 '아 이제 됐다.' 하면서 넘어가지 않으셨나요?
개발 초기에 대량의 데이터가 없을 때는 어떻게든 SQL을 완성하기만 하면 별문제가 없습니다. 해야 할 업무가 많은 상황에서 아키텍처나 SQL 동작 원리를 이해할 만큼의 시간을 내기는 힘든 게 현실입니다. 그러다 보니 IT의 여러 분야에 나타나는 현상 중 '제발 되기만 해라.' 내지는 '(확실하게는 모르겠지만) 이렇게 하면 되는구나'라는 식으로 대충 넘어가거나, 상황을 외우려는 현상이 많이 보입니다. 이미 알고 계시겠지만 이렇게 해서는 앞으로도 실력이 늘기 힘들 것입니다.
그러면 얼마나 알아야 할까요? 첫 연재에서 제시했던 그림들을 다시 한번 보죠.
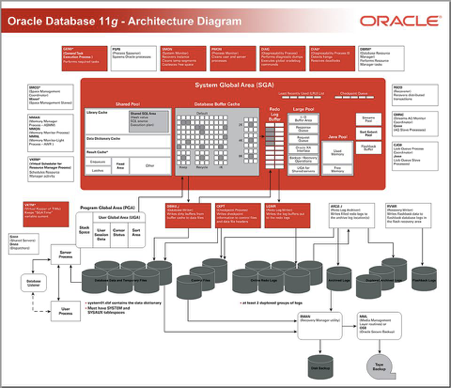
그림 1 오라클 11g 아키텍처(출처: 오라클 홈페이지)
오라클 공부를 이제 시작하는 분들에게 [그림 1]을 보여주고, “여러분 위 그림이 오라클 아키텍처입니다. 하나하나 무엇을 의미하고 어떤 일을 하는지 공부하세요.”라고 한다면 대부분 바로 포기하거나 조금 공부하다가 지치고 말 것입니다. 아주 간혹 매우 열심히 노력해서 [그림 1]의 아키텍처를 다 공부할 사람도 있겠죠. 하지만 어떤 내용이 더 중요하고, 어떤 내용이 덜 중요한지는 이해하기 힘들 것입니다.
핵심이 되는 아키텍처를 먼저 익히고, 오라클의 동작을 이해하는데 조금은 덜 중요한(?) 아키텍처를 채우는 식으로 진행한다면 [그림 1]도 어느 순간에는 쉽게 다가올 수 있다고 생각합니다.
우선, 제가 생각하는 오라클 아키텍처의 핵심은 아래 그림과 같습니다.
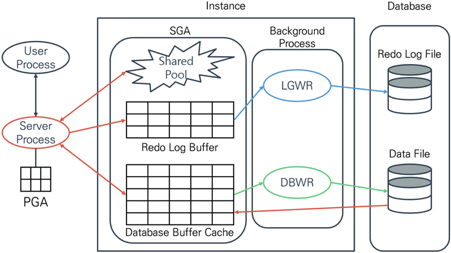
그림 2 오라클 핵심 아키텍처
어떻습니까? 처음 보았던 [그림 1]보다는 좀 시시하다고 생각할 수도 있겠습니다. 또한 그렇게 멋스럽지도 않고요. 하지만 [그림 2]가 오라클을 이해하기 위한 가장 핵심적인 내용이라면 어떻습니까? 이 그림은 한번 해 볼 만하다는 생각이 들겠죠?
사람마다 중요하다고 생각하는 아키텍처가 조금은 다를 수 있겠지만, [그림 2]는 오라클에서 가장 중요하다고 생각하는 아키텍처입니다. 적어도 튜닝 측면에서는 [그림 2]만 어느 정도 이해하면 오라클 아키텍처에서 가장 중요한 핵심을 이해한다고 생각합니다.
오라클 이야기는 잠시 미뤄두고 제가 자동차를 사러 간다고 가정해 보겠습니다. 자동차 전시장에 도착해 문을 열고 들어가면 안내 데스크 직원이 ‘안녕하십니까?’라는 인사와 함께 ‘무엇을 도와드릴까요?’라고 하면서 말을 건넵니다. 자동차를 구경하러 왔다고 하면 데스크 직원이 영업사원 한 분을 소개해 줍니다. 이 영업사원은 전시장의 한쪽에 마련된 로비의 어느 한 테이블로 저를 데리고 가서 제가 원하는 내용에 관해서 설명을 시작합니다. 제가 안내 책자를 보고 싶어하면 잠시 자리를 비워 안내 책자를 가져다주기도 합니다.
전시장에 전시된 차를 구경할 때는 다른 고객들과 서로 섞여서 구경합니다. 다른 고객이 운전석에 앉아 차량을 살펴볼 때는 잠시 기다리기도 합니다. 전시장에서 구경하는 동안에는 줄을 서서 기다리지는 않습니다. 잠시 다른 차에 시선을 돌리다가 다른 고객이 제가 기다리던 차를 먼저 보기도 합니다(래치, Latch). 마음에 드는 차가 있어 시승을 요청합니다. 시승을 위해서는 줄을 서야 합니다. 영업사원이 시승 대기자 명단에 제 이름을 적고 순서를 기다립니다(락, Lock).
시승을 마치고 마음에 무척 들어 구매하기로 했습니다. 영업사원은 서류(계약서, 고객카드 등)를 가지고 옵니다. 저는 계약서와 고객 카드 등을 작성하고 영업사원에게 건넵니다. 영업사원은 제가 작성한 서류들을 다른 직원에게 전달하고 해당 서류를 처리하게 시키기도 합니다. 제 요구사항에 즉각적으로 답을 줘야 하는 상황이라면, 영업사원이 직접 요구사항의 답을 준비하고, 그렇지 않은 경우에는 다른 직원을 시켜서 일을 처리하기도 합니다.
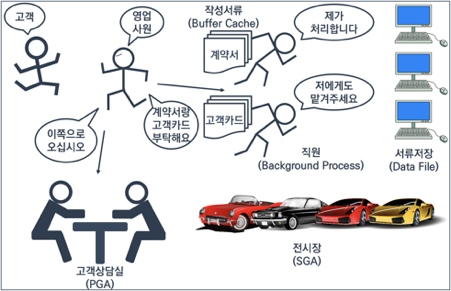
그림 3 자동차 전시장의 비유
이를 오라클로 생각해 보겠습니다. 저에게 처음에 인사하면서 말을 건넨 분은 [그림 2]에서는 없지만, 리스너(Listener)라고 할 수 있습니다. 제가 유저 프로세스라면 영업사원은 서버 프로세스라 할 수 있고요. 여러 고객이 차를 구경하는 전시장은 SGA와 비슷한 개념입니다. 저와 영업사원이 앉아 이야기를 나누는 테이블은 PGA로 볼 수 있습니다.
영업사원은 저의 요구에 답하기 위해 직접 무언가를 가져오기도 하고, 때에 따라서는 다른 직원을 시키기도 합니다. 다른 직원들을 백그라운드프로세스(그림 2에서는 DBWR, LGWR)라 말할 수 있겠습니다. 서버 프로세스에게 무언가를 요청했을 때, SELECT와 같은 실시간으로 결과를 기다리는 경우에는 서버프로세스가 직접 처리합니다. INSERT/UPDATE/DELETE와 같은 일처럼, 처리되었는지만 알면 되는 경우에는 백그라운드 프로세스에게 업무를 시키고 서버프로세스는 다음 요청을 위해 대기합니다.
위 상황과 연결해보면 안내 책자를 보고싶어할 때는 영업사원이 직접 안내 책자를 가지고 옵니다. 고객 등록 처리는 다른 직원에게 시켜서 진행하였습니다. 오라클도 SELECT 요청은 서버 프로세스가 직접 처리하고, INSERT/UPDATE/DELETE 요청은 서버프로세스가 접수해 백그라운드 프로세스에게 시켜서 처리합니다.
이번 장에서는 위에 언급한 몇몇 프로세스의 역할을 설명하고, 오라클이 메모리와 파일을 어떻게 사용하는지와 그 구조는 어떻게 이루어지는지에 대해 공부합니다.
아키텍처를 떠올리며 시작해보기
이제 [그림 2]를 다시 볼까요? [그림 2]에서 인스턴스(Instance) 영역은 메모리와 프로세스를 의미합니다. 데이터베이스(Database) 영역은 물리적인 파일을 의미하고요. 실제 오라클이 어떻게 동작하는지에 대하여 자세히 살펴보겠습니다.
임시 테이블을 한 개 만들고, 예제 INSERT 쿼리문을 하나 만들어 어떤 과정을 거치는지 확인해 보겠습니다. 먼저 INSERT문을 수행하기 전에 테이블을 한 개 만듭니다.
CREATE TABLE INSERT_TEST (NUM NUMBER);
그리고 테스트를 위해 아래 INSERT문을 만들었습니다.
INSERT INTO INSERT_TEST (NUM) VALUES (10);
위 쿼리문을 실행했을 때, 서버프로세스는 실행된 INSERT문이 문법에 맞는지 확인합니다. 그리고 INSERT_TEST라는 테이블이 있는지 또한 NUM이라는 컬럼이 있는지, 거기에 10이라는 값을 저장할 수 있는지를 확인합니다. 또한 SQL문을 실행한 계정이 INSERT_TEST라는 테이블에 INSERT 명령을 할 수 있는 권한을 가지고 있는지 검사하고 모두 통과하면, 이 INSERT문을 재사용하기 위해 해당 쿼리를 Shared Pool에 저장합니다. 쿼리가 실행되면 10이라는 값을 Redo Log Buffer에 저장합니다. 그리고 곧바로 Database Buffer Cache(이하 DB Buffer Cache)에 저장합니다.
쿼리문을 실행한 순간에 아직 물리적으로 파일에는 데이터를 저장하지 않았습니다. 그러다 COMMIT 명령을 내리면 LGWR(Log Writer)이라는 프로세스가 Redo Log Buffer에 있는 내용을 Redo Log File에 저장합니다. 이 때 DB Buffer Cache는 Dirty Buffer로 상태가 바뀌고 Checkpointer는 Data File에 저장하기 위해 DBWR(Database Writer)에게 신호를 보내고 DBWR은 Data File에도 기록합니다.
자동차 전시장 상황과 한 번 더 비교해 보자면 영업사원(서버프로세스)은 고객카드가 잘 작성되었는지 먼저 확인해 보고(위의 몇 단계에 걸친 검사들) 이상이 없으면 다른 직원(LGWR)을 불러 고객 카드로 고객 등록을 하라고 시킵니다.
이번엔 SELECT문으로 확인해 보겠습니다.
SELECT * FROM INSERT_TEST;
INSERT문과 마찬가지로 서버프로세스는 실행된 SELECT문이 문법에 맞는지 확인합니다. 위에서와 같은 순서로 SELECT문이 문법에 맞게 작성되었는지 확인하고, 쿼리문에 열거된 테이블명, 컬럼명 등이 실제로 있는지 확인한 다음에, SQL문을 실행한 계정이 INSERT_TEST라는 테이블에 SELECT명령을 수행할 수 있는 권한을 가지고 있는지 확인합니다.
이 과정을 통과하면, 이 SELECT문을 재사용하기 위해 Shared Pool에 저장합니다. 이제 데이터를 가져오게 되는데 INSERT_TEST 테이블의 데이터가 어디에 있는지 확인합니다. 서버프로세스는 먼저 DB Buffer Cache에 있는지 확인하고, 없으면 디스크에 가서 해당 테이블 데이터를 DB Buffer Cache로 복사합니다. DB Buffer Cache에 적재된 데이터 중 SQL문의 결과를 유저프로세스로 전송합니다. 안내 책자를 원했을 때, 영업사원이 직접 안내 책자를 가져오는 과정과 비슷합니다. 이 때 로비에 준비된 안내 책자가 소진되었다면 사무실(디스크)에 가서 안내 책자를 가져오겠죠.
여기까지 간략하게 INSERT문과 SELECT문을 통해 쿼리문을 실행했을 때, 데이터가 어떤 경로를 거쳐 이동하는지 확인해 보았습니다. 위 내용을 정리하면 다음과 같습니다.
INSERT
- SQL문의 문법을 확인합니다(문법 검사 또는 키워드 검사: INSERT, SELECT, FROM, WHERE 등).
- SQL문에 있는 테이블과 컬럼을 검사합니다(의미 검사).
- SQL문을 실행한 계정의 권한을 검사합니다(권한 검사).
- Redo Log Buffer에 기록합니다(INSERT, UPDATE, DELETE문에 해당).
- LGWR(Log Writer)이 Redo Log File에 기록합니다.
- DB Buffer Cache에 기록합니다(INSERT, UPDATE, DELETE문에 해당).
- DBWR(Database Writer)이 Data File에 기록합니다.
SELECT
- SQL문의 문법을 확인합니다(문법 검사 또는 키워드 검사: INSERT, SELECT, FROM, WHERE 등).
- SQL문에 있는 테이블과 컬럼을 검사합니다(의미 검사).
- SQL문을 실행한 계정의 권한을 검사합니다(권한 검사).
- DB Buffer Cache에서 테이블 데이터를 찾습니다.
- DB Buffer Cache에 없을 경우, 디스크에서 찾아 DB Buffer Cache로 복사합니다. SELECT 결과 데이터를 유저프로세스로 전송합니다.
지금까지 대략적인 내용을 살펴보았습니다. 여기서 조금만 더 발전시켜서 더 세부적으로 살펴보겠습니다.
위에서 보면 오라클에 데이터를 저장할 때와 이미 저장된 데이터를 불러오는 구조는 전혀 다르다는 것을 알 수 있습니다. SQL문을 확인하는 과정은 같다고 볼 수 있지만 데이터를 쓸 때는 LGWR과 DBWR이 관여하고, 불러올 때는 서버프로세스가 관여합니다.
참고: 어느 프로세스가 저장하는 데이터가 더 중요할까?
LGWR과 DBWR 두 개의 프로세스 중에서 어느 프로세스가 저장하는 데이터가 더 중요할까요? 오라클은
데이터베이스입니다. 갑자기 뜬금없이 당연한 얘기를 하냐구요?
오라클은 어떠한 상황이 오더라도 복구가 가능하도록 데이터베이스를 설계해야 하는데,
최악의 상황이라면 두 데이터 중에서 오라클은 어느 데이터를 보장할까요? 바로 Redo Log File입니다.
Redo Log를 적절하게 디스크로 기록해야 합니다.
또한 결국 데이터는 Data File에 저장되기 때문에 이 또한 중요하지 않다 말할 수 없습니다.
다음 회에는 ‘오라클 아키텍처 이해 하편’으로서 지금까지 설명한 내응을 좀 더 세부적으로 알아보겠습니다. 다음 회에 뵙겠습니다. 감사합니다. (다음 회에 계속)
댓글
댓글 0개
댓글을 남기려면 로그인하세요.